はじめに
こんにちは。医療プラットフォーム本部ビジネス基盤グループでエンジニアをしている熊本です。
ブログへの登場は久々となりますが、2019年に新卒で入社して以来、長らくプロダクト開発のエンジニアをしてきました。そんな私は現在、医療プラットフォーム全体のMA(マーケティングオートメーション)、SFA(営業支援)、CRM(顧客管理)といったITツールおよび業務フローの設計・改善を通じて、事業パフォーマンスの向上を担う開発組織のマネージャーを務めています。
メドレーでは、患者・生活者と、病院・有床診療所、医科診療所、歯科診療所、調剤薬局といった各医療機関向けに事業・プロダクトを展開していますが、今回は、これらの事業を支えるITツールのSalesforceをkintoneへ移行したプロジェクトについてお話しします。
背景
SFAが抱えていた課題
弊社では長年、医療プラットフォームにおける複数の事業部門で共通のSalesforceを利用してきましたが、運用を続ける中で以下のような課題が顕在化していました。
- 最新・正しい情報の把握が困難:正規化されていないデータや重複管理による情報の分散
- データ分析の壁:分析を見据えた設計になっておらず、プロダクト側の利用状況との突合など、柔軟なデータの加工に工数がかかっていた
- 非効率な業務フロー:複数ツールの併用や重複する項目の存在などを背景に、手動での転記やダブルチェックが発生している状態
- システム管理の属人化:目的が不明な項目が乱立し、メンテナンス・レポート作成ができる人が限られている状態
また、130個近くのライセンスを保有していたため、これらの課題を踏まえるとコスト過多な状況にも陥っていました。
全ての顧客体験をプロダクト側が理解し、設計責任を持つ
私たちは、営業・カスタマーサクセスといった顧客活動から、契約・請求に至るまでを「一連のプロダクト体験」として捉え、その設計・実装にエンジニアが深く関わることを大切にしています。
この考えに基づき、単なるツールのリプレイス(お引っ越し)ではなく、より良い顧客体験につながる合理的で整理された事業オペレーションを実現するため、業務・データ・ツールを一体でエンジニアが設計し直す。これが本プロジェクトの重要なポイントでした。
取り組み
体制構築とアーキテクチャ設計
前述の通り、Salesforceはこれまで複数の事業部門で活用してきました。1人で各事業の業務フローや必要データを把握し再設計するのは困難ですし、何より私たちが大切にしている考え方も踏まえ、プロダクトエンジニアが各事業に深く潜り込んで再設計すべきだと考えました。そこで、各事業領域からプロダクトエンジニアを1名ずつアサインする体制としました。私はPMとして全体設計や車輪の再発明が起きないよう各部門の連携をコントロールする役割を担い、各環境のデータ設計・構築はその事業領域担当のエンジニアが主導する形をとりました。
kintoneは責務分離やメンテナビリティを考慮し、事業領域ごとに環境を分けるアーキテクチャを採用しました。また、kintoneへの移行に伴い、コストや親和性を加味してMAツールの移行も行いましたが、本記事では詳細を割愛させていただきます。
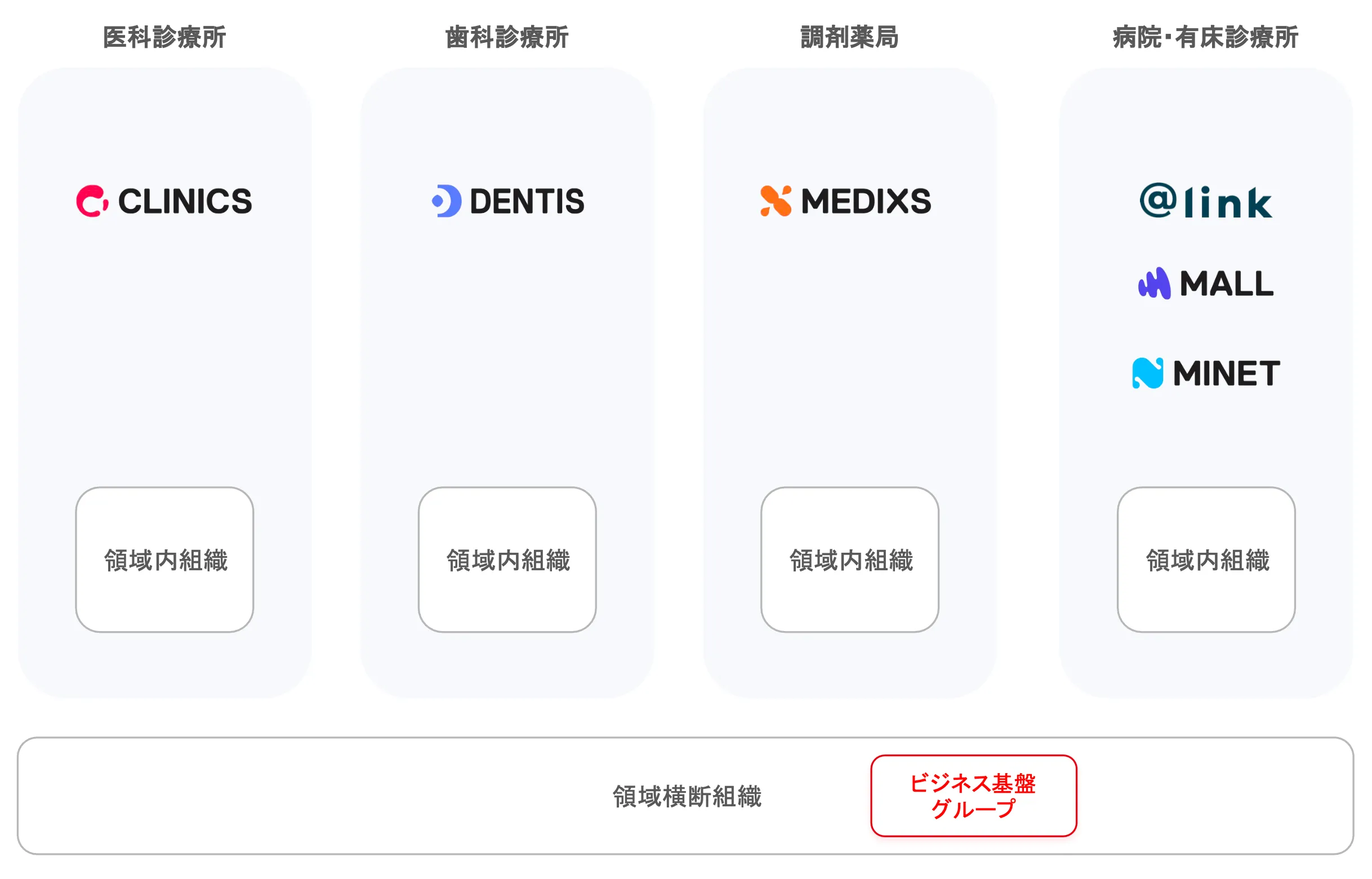
医療プラットフォーム本部の組織体制
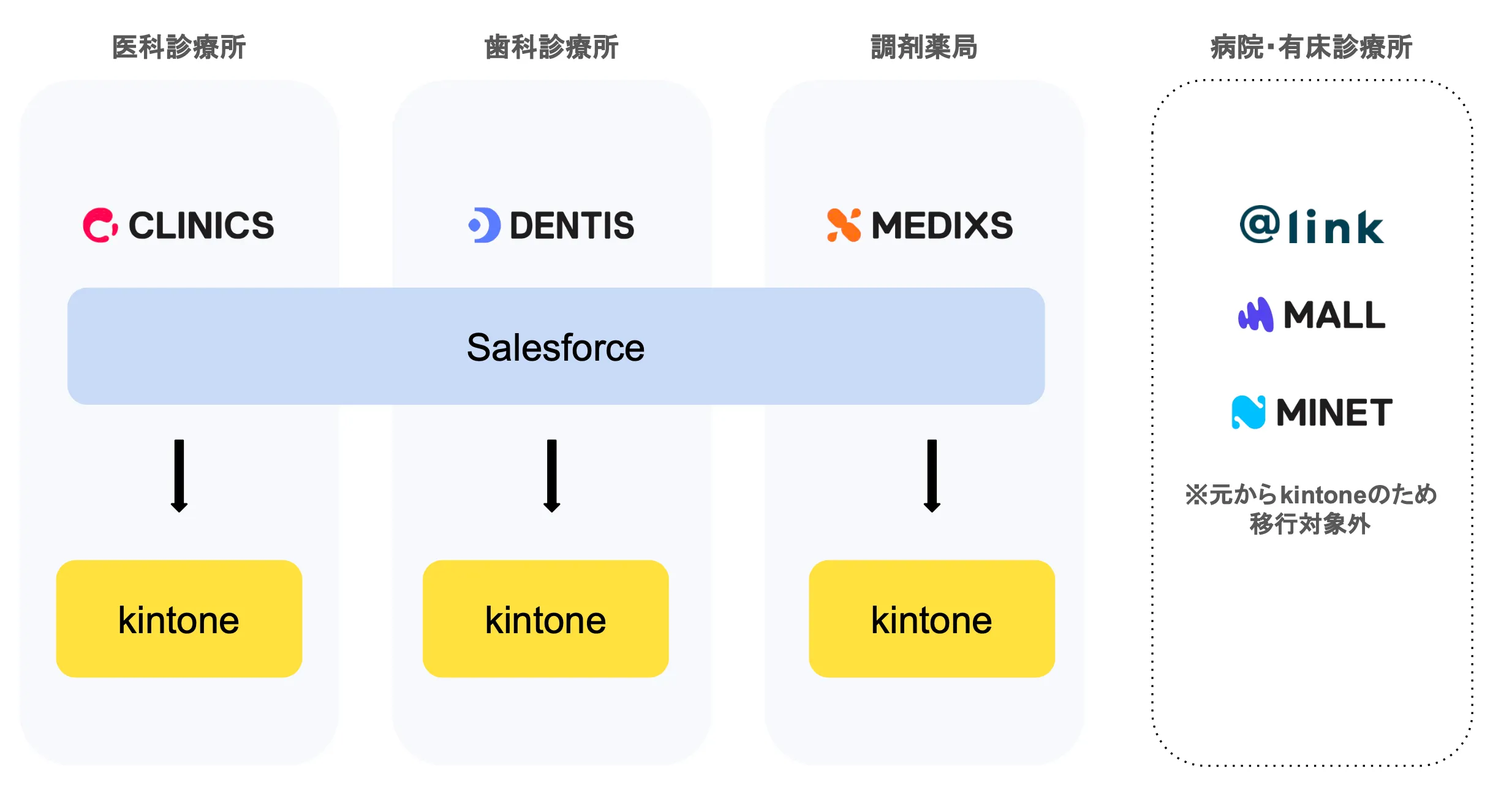
ツールの移行イメージ
業務理解と要件定義
まずは、日々の事業活動の中で発生するデータや、業務上必要となるデータ、およびそのフローの現状とあるべき姿を描くため、事業部とコミュニケーションを重ねました。長年利用してきたこともありデータ項目が膨大となっていたため、「このデータをどう活用するのか」を重点的に会話し、そもそも不要ではないか、より活用しやすくするにはどうすべきか、などの整理に時間をかけました。
データ設計
特に工夫したのは、DB観点での「正規化」とユーザー観点での「入力のしやすさ」のバランスをとったデータ設計です。kintoneはDBとUIが一体型であるため、このバランス調整にとても苦労しました。一般的なRDBMSではデータの履歴を残すために専用のテーブルを設けイミュータブルモデリングなどを採用する場面でも、kintoneだとテーブル≒アプリとなるため、テーブルを分けることは単純にユーザーの画面遷移や入力箇所を増やすことに直結してしまいます。こういった場合は完全な正規化をするのではなく、普段の商談管理で使用するアプリとその商談ステータスの履歴を管理するアプリを分け、それぞれのアプリに同類のフィールド(RDBMSのカラムをkintoneではフィールドと呼びます)を設置することを許容しつつも、JavaScriptを用いた自動転記の仕組みを作ることで、ユーザーは商談管理アプリだけに入力していれば良いようにするといった工夫をしました。
泥臭く戦ったポイント:データ移行と同期システム
ここからは、エンジニアとして特に苦労した2つのポイントをご紹介します。
1. 冪等性と再現性を追求したデータ移行
100名以上が利用するシステムにおいて、特にデータ移行には慎重を期しました。具体的な方法としては、Salesforceのスキーマをkintoneのスキーマに変換し、データをマッピングした結果をCSVに出力するという一連の処理を、CLIコマンド等の整備によりスクリプト化しました。
データ移行では、一度kintoneに投入した後、UAT期間中に事業部からのフィードバックを受けて設計を見直し、再投入が必要になるケースがありました。また、リハーサル目的で、本番移行前にも何度でも再実行できる仕組みが必要でした。そのため、前述のように一連の処理をスクリプト化し、「再現性」を確保しました。さらに、「冪等性」も重要なポイントでした。今回のケースでは、それぞれのアプリにユニークキーを設けて常にUPSERT処理を行うことで、元データが同じであれば、何度実行しても同じ状態を再現できるようにしました。
kintoneへのインポート処理自体はレコード数に比例して一定の時間がかかってしまうものの、事前に手順化しリハーサルを重ねたことで、本番稼働前日の夜間作業で無事に移行を完了させることができました。ただし、(一定の想定範囲ではあったものの)移行作業直前にSalesforce側でデータの更新や削除が行われたことで、kintone側で関連データ同士の紐付けがうまく設定できないケースも発生しました。これはエラーログを見て個別に対処するしかなく、大変苦労した部分でもありました。
2. Salesforceとkintoneの双方向同期システム
Salesforceは長年活用してきたことから、いわゆるSFAとしての機能だけではなく、請求や契約管理としての役割も担っていました。今回のプロジェクトでは事業部側が利用するSFAとしての機能はkintoneへ移行しつつも、請求や契約管理といったバックオフィス領域に関しては将来的な販売管理システムへの移行も見据えてスコープ外としていました。よって、これまでは一つのシステムの中で顧客・商談から契約・請求まで一元管理していたものを分離したため、システム間でデータを連携させる必要がありました。
詳細は省きますが、Salesforceに残った契約・請求関連データの一部は、営業やカスタマーサクセスなどの事業部側と契約・請求処理を担うバックオフィス部門の双方向による書き込みが業務上必要であったため、単にkintoneから必要なデータを一方向で送るだけでは要件を満たせませんでした。そのため、SFA領域とバックオフィス領域のハブとなる「商談」などのデータに関しては、Salesforceとkintone間で一部のスキーマ定義を揃え、両システムを一定間隔で同期させる仕組みとしました。
具体的な仕組みとしては、両システムのスナップショットを一定間隔で取得し、前回との差分を検知して互いのシステムへ反映し合う形をとりました。 ここで壁となったのが、「準リアルタイム性」の要求と「データの競合」です。両方のシステムで日常的にトランザクションが発生するため、「同じレコードの同じ項目が、それぞれのシステムで同時に別の値へ書き換えられる」可能性がありました。この競合状態を安全に解決するためのロジックを構築する必要があり、非常に苦労しました。 この対応にあたっては、当初想定していた対象項目が、本当に準リアルタイムで同期が必要なのかを関係者と徹底的に精査しました。その結果、同期間隔の調整や同期対象の大幅な絞り込みができ、現在は安定して稼働する仕組みを実現できています。
※ データ移行や同期処理のディープな話は盛りだくさんな内容となってしまうため、また別の機会にブログ化できればと思います!
成果
80%以上のランニングコスト削減
契約・請求などを担う組織の必要分を除き、90個ほどのアカウントを削除することができました。kintoneの費用を加味しても、全体のランニングコストとして80%以上削減することができました。
BigQuery集約によるデータ分析・可視化の実現
Salesforceのレポート機能の制約から解放され、より柔軟なデータ活用ができるようになりました。
- KPIダッシュボードの構築:Looker Studioなどのアセットと連携したデータの分析・可視化が可能に
- 自律的な分析文化:勉強会の開催やマニュアル整備のおかげもあり、事業部メンバーが生成AIも活用しながら、より自律的かつスピーディなデータ分析が可能に
- 横断的分析:kintoneの顧客・商談データ、契約データ、プロダクトデータなどをBigQueryに集約し、多角的な分析を実現
また、横断組織にあるデータ戦略グループが、最近「自然言語でBigQuery等のデータを分析できる社内システム」をリリースしました。今回のプロジェクトによるデータ整備とこのシステムが組み合わさり、よりスピーディにデータ分析を行える環境づくりが加速しています。
関連記事:データ分析AIエージェントの実践 - Slack × Devin × Context Engineering
今後の展望
本プロジェクトによって多くの成果を得られましたが、私たちはまだ「業務やデータの一部をツールの移行と共に再設計し、基盤を整えた」に過ぎません。
今後はこの基盤を活かし、KPIなどの定量的なデータや現場ヒアリングを通じて事業の課題・ボトルネックを特定し、継続的に改善を回すサイクルを作っていきたいと考えています。
また、日々顧客と向き合う事業部のメンバー自身が、データ活用や拡張性を見据えて自律的にツールを改修できる状態こそが、組織のアジリティを最も高く保ちながらスケールできる理想の形だと考えています。その実現に向けて、エンジニアリングの専門性を持つ私たちビジネス基盤グループが、誰もが改修・改善しやすい仕組みづくりを牽引していきたいと考えています。
まとめ
エンジニアが事業の深い部分に入り込み、業務・データ・ツールを一体で再設計するプロジェクトについてご紹介させていただきました。
メドレーでは、「医療ヘルスケアの未来をつくる」というミッションのもと、エンジニアがビジネスの根幹に関わり、プロダクトと事業を共に成長させる文化があります。自ら課題を発見し、設計から運用までをエンジニアとしてのリーダーシップを発揮しながら一気通貫で推進できる方を絶賛募集しています。

少しでも興味を持っていただけましたら、ぜひメドレーの採用ページをご覧ください!