はじめに
医療プラットフォーム本部 プラットフォーム開発室 SREグループの吉田です。医療機関向けSaaSであるCLINICSの安定稼働とシステム信頼性の向上に取り組んでいます。
CLINICSではメインDBとしてMongoDBを使用しており、以下の3つの目標を掲げて、DBM(Database Monitoring)を導入しました。 なおCLINICSでは監視・オブザーバビリティ基盤としてDatadogをすでに活用(*1)していたため、Datadog DBM(Database Monitoring)を採用しました。
- クエリのパフォーマンス課題の早期検知
- スロークエリの改善サイクルの向上(回数を増やす・サイクルを短くする)
- スロークエリのナレッジを蓄積
背景・課題
DBM導入前の運用
MongoDB AtlasからログをダウンロードしてCOLLSCANや実行時間を分析するスクリプトを運用していました。分析の粒度はコレクション名とFind/Commandの種別に加えて、クエリシグネチャ単位での詳細な分析も行っていました。この作業を週次で実施し、スロークエリを発見・改善するサイクルを回していました。
課題
- 先週比の悪化検知ができない:スクリプトによる分析はある時点のスナップショットにとどまるため、時系列での比較・悪化検知が困難だった
- 本番の実行計画を取得できない:Atlasのログには詳細な実行計画が含まれないため、クエリ改善に必要な情報が不十分だった
- スロークエリのナレッジが再利用しづらい:Google スプレッドシートにスロークエリの対応履歴を記録していたが、AI エージェントによる検索性に課題があり、過去の対応内容を参照しづらい状況だった
- 手動ログ取得に工数がかかる:MongoDB Atlas の本番 DB からログを手動でダウンロードする運用となっており、1週間分のログ取得に時間がかることから、毎週約1時間の作業工数が発生していた。
解決策の全体像
DBMの導入により、以下の方法でそれぞれの課題を解消しました。
- 先週比の悪化検知ができない:Datadog Dashboard を活用することで解消。週次での傾向比較やパフォーマンス悪化が検知可能に。
- 本番の実行計画を取得できない:DBMに内包されるクエリサンプリング機能により解消。実行計画(explain plan)をリアルタイムで取得・可視化できるため、クエリ改善に必要な情報を直接確認。
- スロークエリに関するナレッジが再利用しづらい:対応方針や問題視した観点などをGitHub Issueに記録。
- 手動ログ取得による作業工数:Datadog DBM によりスロークエリの収集・分析が自動化されたため、この部分の工数がゼロに。
以下が、システム構成図です。

大きく3つのステップで構成されています。
- Datadogダッシュボードの構築:DBMを用いてスロークエリ・COLLSCAN・クエリ効率を可視化
- Goスクリプトによるデータ取得:ダッシュボードの内容をJSON形式で取得し、Claude Codeが対応優先度を判定
- GitHub Issueの自動生成:優先度が高いクエリのみをIssue化し、対応漏れを防ぐ
実装の詳細
Datadogダッシュボードの構築
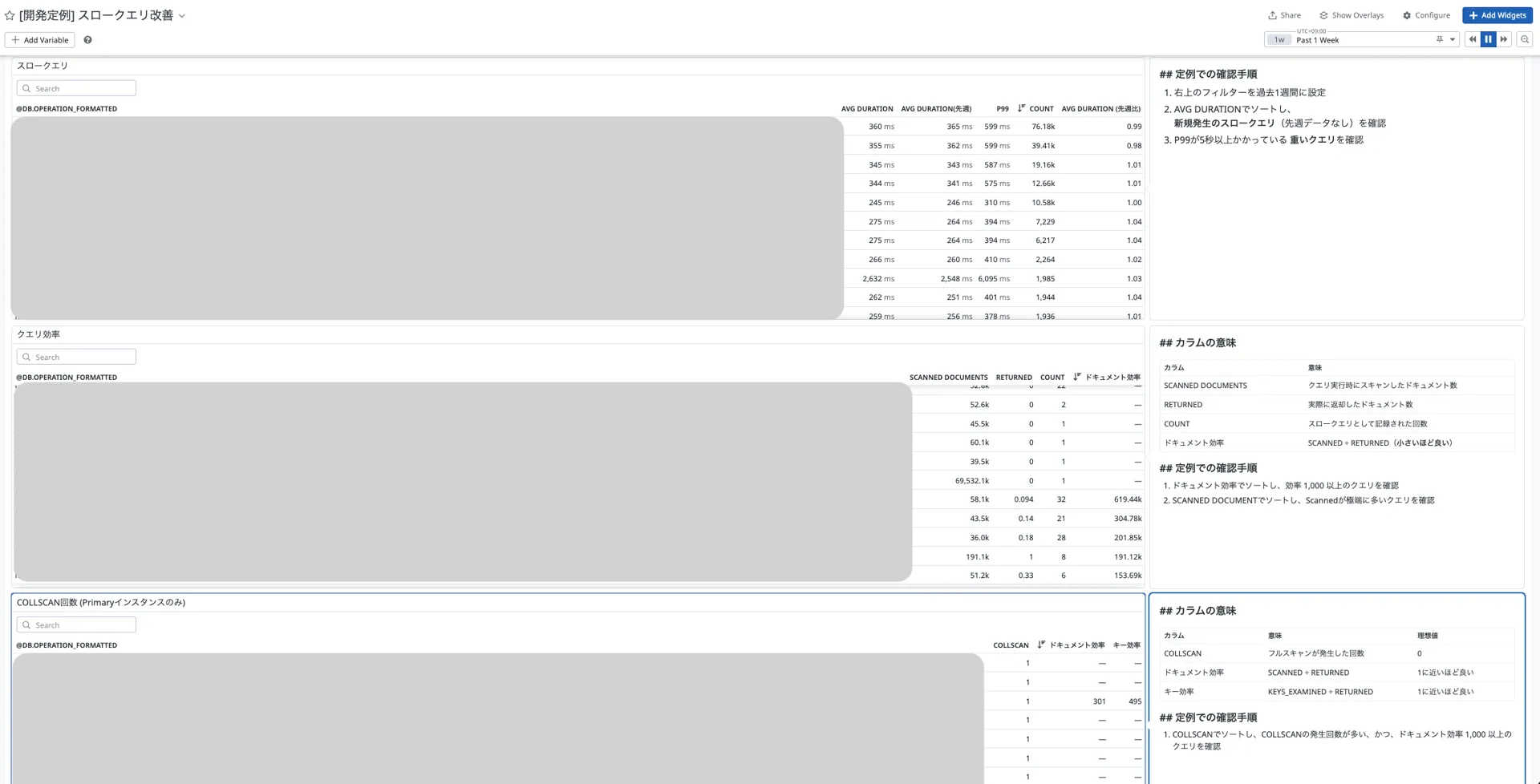
DBMを導入し、以下の3つの観点でダッシュボードを構築しました。
| 観点 | 検出条件 |
|---|---|
| COLLSCAN | プライマリーインスタンスで発生しているフルスキャンを特定 |
| クエリ効率 | クエリ効率が1,000以上かつドキュメントスキャン数が多いクエリ |
| 新規スロークエリ | 先週比で新たに発生したスロークエリを特定 |
以下は、実際に作成したDatadog Dashboardです。
Goスクリプトによるデータ取得と優先度判定
ダッシュボードで取得している内容をJSON形式で取得するGoスクリプトを作成し、事前に定めたルールに基づいて、Claude Codeが優先度を判定します。
優先度は以下を使用しました。
- PrimaryインスタンスでのCOLLSCANが発生しているクエリ
- クエリ効率が1000以上かつ、ドキュメントスキャン数が多いクエリ
- 新規発生のスロークエリ
取得しているメトリクスは以下です。
| メトリクス | 用途 |
|---|---|
@mongodb.plan_summary (collscan_countを算出) | インデックス未使用のフルスキャン検出 |
@mongodb.docs_examined, @mongodb.nreturned (docs_efficiencyを算出) | クエリ効率の評価 |
@duration (avg_duration_ns / p99_nsを算出) | 今週・先週の実行時間比較 |
pup 未対応による直接API呼び出し
ダッシュボードの内容取得にあたり、2026年2月にリリースされた https://github.com/DataDog/pup の使用も検討しましたが、DBMのパフォーマンス結果を集計する /api/v2/query/scalar APIに未対応だったため、APIを直接呼び出す形で実装しました。
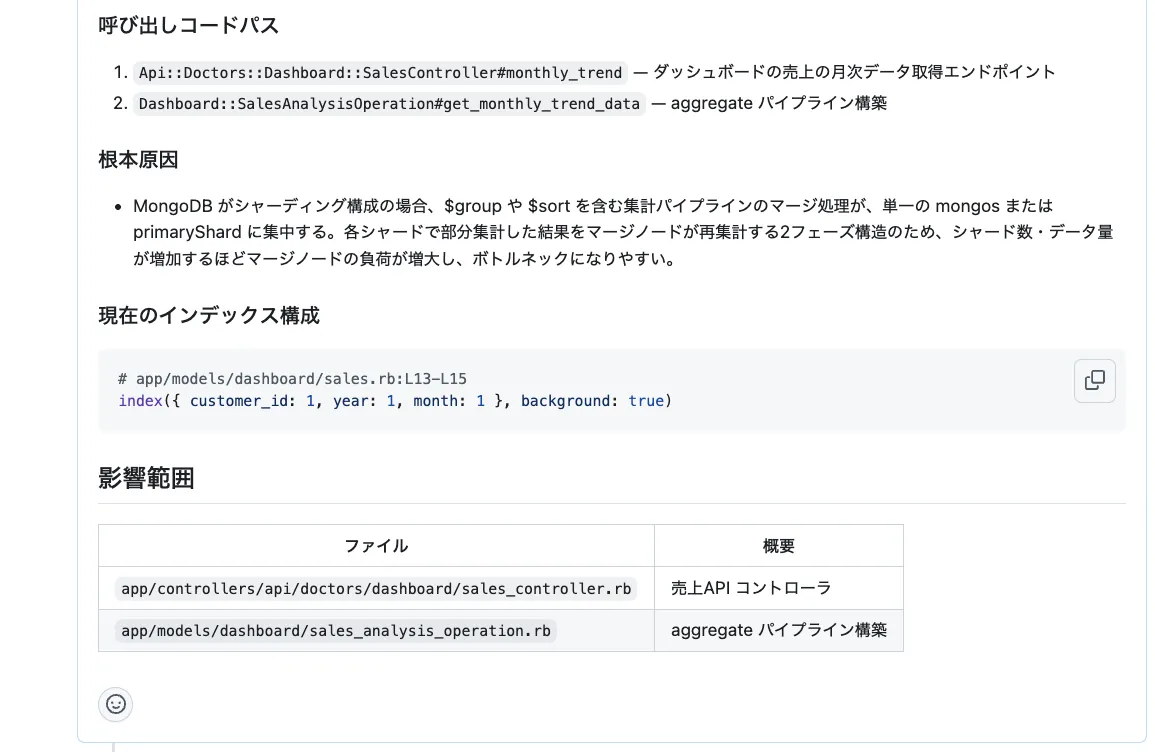
呼び出し元の特定
なお、CLINICSではAPIと非同期ジョブそれぞれにミドルウェアを自作し、MongoDBクエリにAPIパスやJobクラス名をコメントとして付与する仕組みが既に導入されていました。 コメントがDBMに連携されることで、Datadogコンソール上のクエリ詳細画面にAPIパスやJobクラス名が直接表示されるようになりました。これにより、スロークエリが発生した際にどのコードが起点かをコンソール上で即座に確認できます。以前はMongoDB Atlasからログをダウンロードし、スクリプトを実行してコメントを抽出する必要があったため、1件の呼び出し元特定に数分かかっていました。この手順がなくなり、調査の初動が大幅に短縮されました。
GitHub Issueへの自動登録
QuerySignatureによるIssue管理
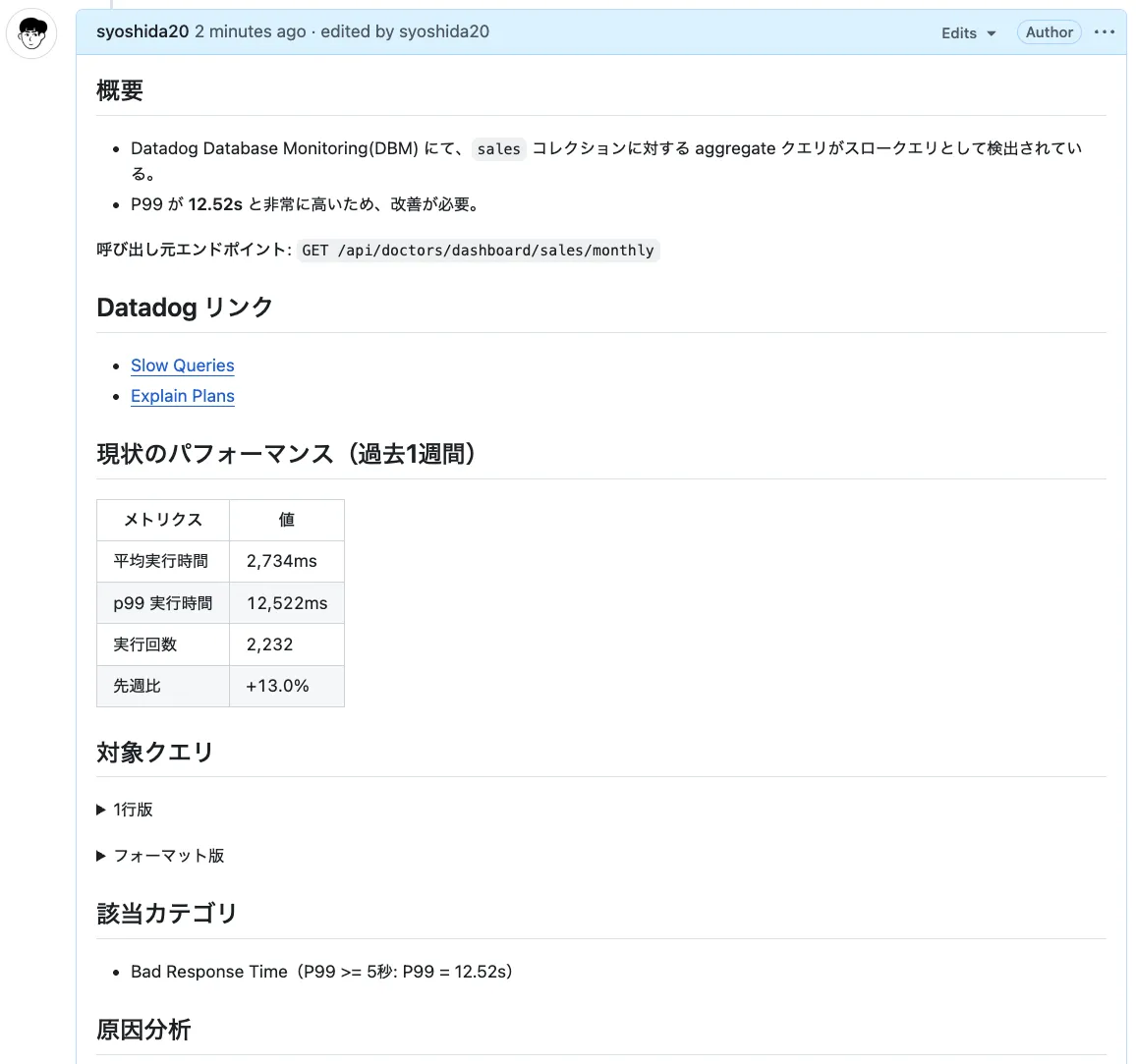
スロークエリを一意に識別できるよう、スロークエリ専用のTagをGitHub 上で作成し、IssueのタイトルにQuerySignatureを含めるようにしました。 これにより、同一クエリの重複Issue作成を防ぎ、過去の対応履歴をIssueで追跡できます。
(例) 【スロークエリ改善】sales - 売上月次比較 aggregate クエリ (qs:bed4b54513c9204e)改善困難クエリのナレッジストック
問題はあるが解消が難しいクエリ(例:クエリ対象をMongoDBからOpenSearchに変更する必要があるケースなど)はIssueにストックしておき、 既知のクエリとして扱うことで新規スロークエリの検出に集中できるようにしました。
以下は、サンプルのGitHub Issueです。(*2)
Claude Codeスキルとしての統合
上記の「Goスクリプトによるデータ取得・優先度判定」と「GitHub Issueへの自動登録」の一連のステップは、Claude Codeのスキルとしてまとめています。週次作業時はこのスキルを実行するだけで、スロークエリの検出からIssue生成までが自動的に完了します。
効果
- 週次の作業工数を1時間から10分に削減:MongoDB Atlasからログをダウンロードして手動で分析していた作業が、Claude Codeスキルにまとめられ、スキルの実行と結果の確認のみになり、週次の作業工数を削減できました。
- スロークエリのナレッジを蓄積できる基盤の構築:改善困難なクエリや過去の対応履歴をGitHub Issueにストックすることで、スロークエリに関するナレッジを体系的に蓄積・参照できる基盤を整えることができました。これにより、新規スロークエリの検出に集中できるようになり、チーム内での知見共有も容易になりました。
今後の展望
今回はパフォーマンス課題の発見・Issue化までを自動化しました。最終的には「AIが課題を発見しPRを作成し、人間が責任を持ってリリースする」サイクルの実現を目指しており、次のステップを検討しています。
- PR作成の自動化:AI推進グループ(*3)と連携し、インデックス追加などのPR作成まで自動化します。
- スロークエリデータの長期保存基盤の構築:Datadog DBMのデータ保持期間は2週間であるため、現状では長期的なトレンド分析ができません。Goスクリプトで取得したデータをS3に蓄積し、Athenaで分析する基盤を構築することで、月単位・四半期単位でのパフォーマンス推移の可視化や、改善施策の効果測定を可能にします。
- パフォーマンス評価の自動化:DBメトリクスも合わせて総合的な評価を行います。
まとめ
- Datadog DBMの結果からルールベースでスロークエリを自動検出し、Claude Codeスキルを活用してGitHub Issueを自動生成する基盤を構築しました。
- 最終目標はAIがパフォーマンス課題の発見からPR作成までを担い、人間が責任を持ってリリースすることです。
- 本記事ではその第一歩として、課題の発見・Issue化までの自動化を解説しました。
メドレーでは、SREをはじめ「医療ヘルスケアの未来」を共に創っていくエンジニアを大募集中です!少しでもご興味をお持ちいただけましたらぜひ、ご応募お待ちしております!


※カジュアル面談も大歓迎です!ご希望の際は、「その他の項目(希望記入欄)」にてその旨をご記載ください。
注釈
*1: CLINICSでのDatadog活用事例については、こちらの記事を参照ください。
*2: 具体的なデータは、全てダミーデータを使用しています。
*3: AI推進グループは、「AIで『医師』と『エンジニア』の生産性を最大化する」というミッションのもとで、プロダクトへのAI機能導入と開発者の生産性向上に取り組む組織です。詳しく知りたい方は、以下を参照ください。
