はじめに
こんにちは、医療プラットフォーム本部データ戦略グループの安東です。
以前、私たちは「データ戦略グループにおけるcontext engineeringの取り組み」という記事で、LLMに適切なコンテキストを提供することで分析精度を向上させるContext Engineeringの実践について紹介しました。
本記事は、その取り組みをさらに一歩進め、ビジネスユーザーが日常的に使える分析AIエージェントとして社内リリースした事例を紹介します。
組織拡大に伴うデータ分析ニーズ増加とアナリスト不足という課題に対し、私たちはContext Engineeringの知見を活かし、Devinを分析AIエージェントとして活用した分析基盤を構築しました。
本記事では、Slackをインターフェースとした分析AIエージェントのアーキテクチャと、データ戦略グループの具体的な取り組みについて解説します。
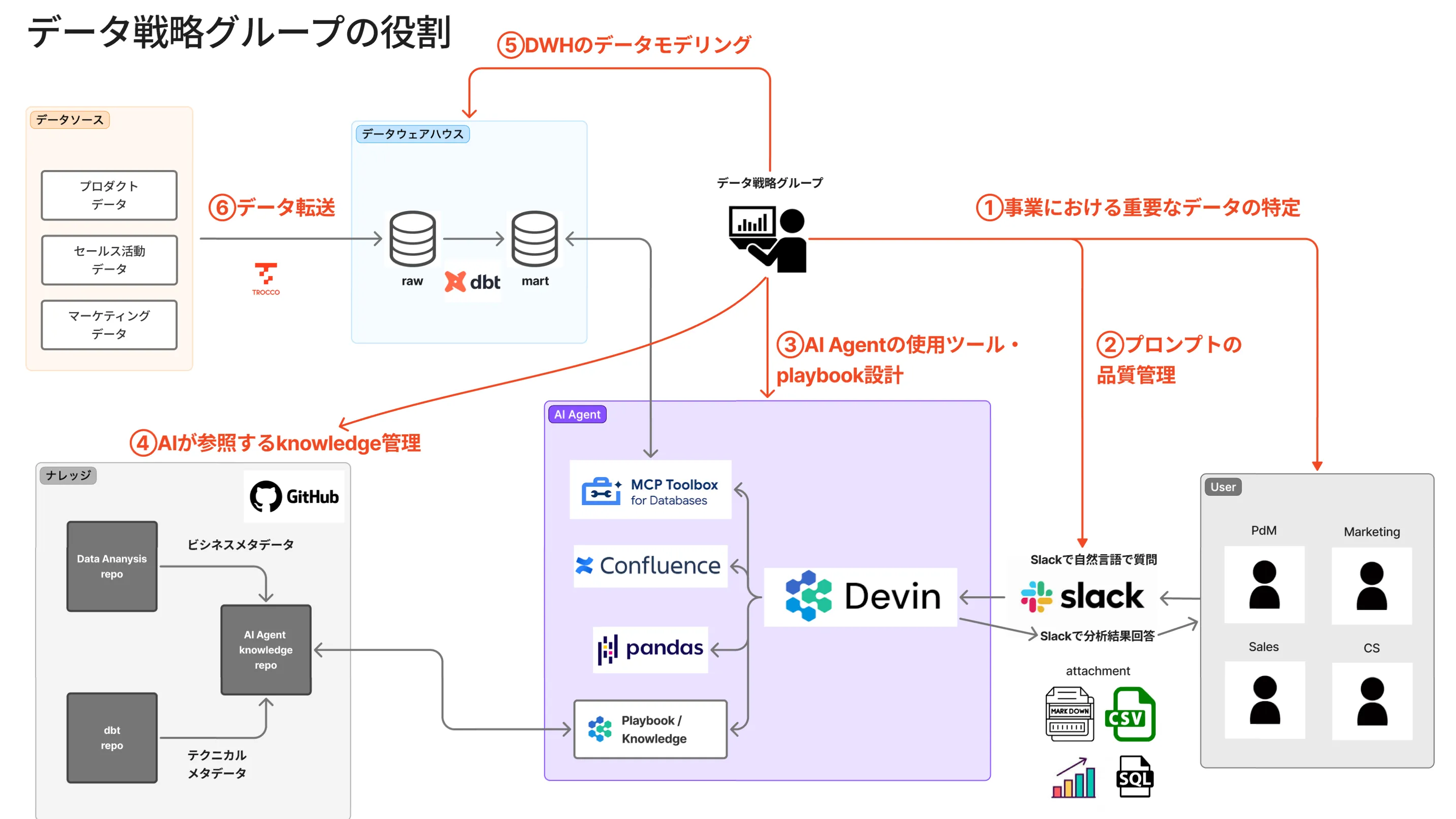
分析AIエージェントの全体フロー
分析AIエージェント全体の流れを以下の図で示します。
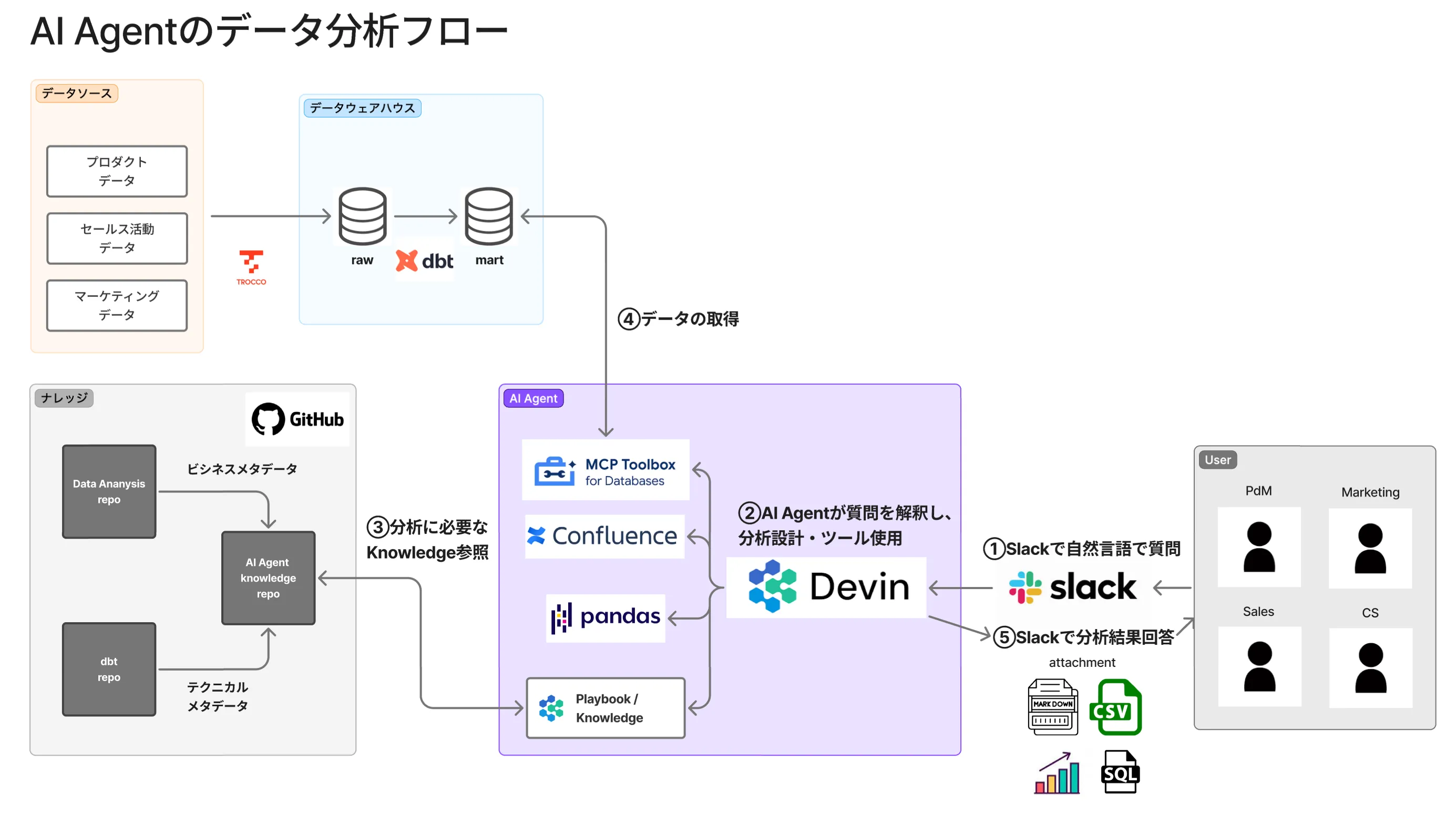
分析は、次の5つのステップで実行されます。
① Slackで自然言語で質問
ビジネスユーザー(PdM、Marketing、Sales、CSなど)が、Slackで自然言語により分析を依頼します。
分析依頼の専用フォームを用いることで、分析の目的、対象プロダクト、希望スピードなどを構造化して入力できます。
② AIエージェントが質問を解釈し、分析設計とツール使用
Devinが中心となり、以下のツールを活用しながら分析を設計・実行します。
- MCP Toolbox for Databases: データベースへのアクセス
- Confluence: 社内ドキュメントの参照
- pandas: データ分析とグラフ作成
- Playbook/Knowledge: 分析設計とドメイン知識の参照
③ 分析に必要なKnowledge参照
GitHubに格納されたKnowledgeリポジトリから、必要な情報を取得します。
- ビジネスメタデータ: プロダクト固有のビジネスロジックやKPI定義
- テクニカルメタデータ: データモデルの構造や分析手法
④ データの取得
データウェアハウスから分析に必要なデータを取得します。
データはdbtで変換されたmartモデルを中心に、分析パスに応じて最適なレイヤーにアクセスします。
⑤ Slackで分析結果回答
Slackのスレッドに、以下の形式で分析結果を返却します。
- 分析の結果・要約
- Markdown形式のレポート
- CSV形式のデータ
- グラフ(PNG、HTML)
- 実行したSQLクエリ
この一連の流れにより、ビジネスユーザーはSlack内で数分で分析結果を得られます。
データ戦略グループの取り組み
データ戦略グループとして、この分析フローを実現するためにどのような工夫を行っているのか、具体的に解説します。
① Slackインターフェース:ユーザー体験の最適化
なぜSlackなのか
ビジネスユーザーにとって、データ分析の障壁は、「そもそも分析を依頼すること自体が難しい」という点にあります。
SQLエディタを開く、分析の設計をする、アナリストに分析依頼することは、多くのビジネスユーザーにとって日常的な行動ではありません。
一方、Slackは多くの組織で既に日常的に使われているツールです。メッセージを送る感覚で分析を依頼できれば、認知負荷を最小化できます。
私たちはこの点に着目し、Slackを分析AIエージェントのインターフェースとして選択しました。
フォーム設計による「プロンプトの最適化」
しかし、Slackで自由フォーマットで依頼を受けると、AIエージェントが意図を正しく汲み取れず分析品質がブレてしまいます。
そこで、構造化フォームを用いることで、分析に必要な情報を確実に収集し、AIエージェントへの入力を最適化する設計としました。
従来アプローチ: 自由記述 → AIエージェントが意図を推測 → 品質がブレる
改善アプローチ: 構造化フォーム → 必要情報を確実に収集 → 品質が安定分析フォームは試行錯誤中ですが、分析設計において重要な情報を必須にしています
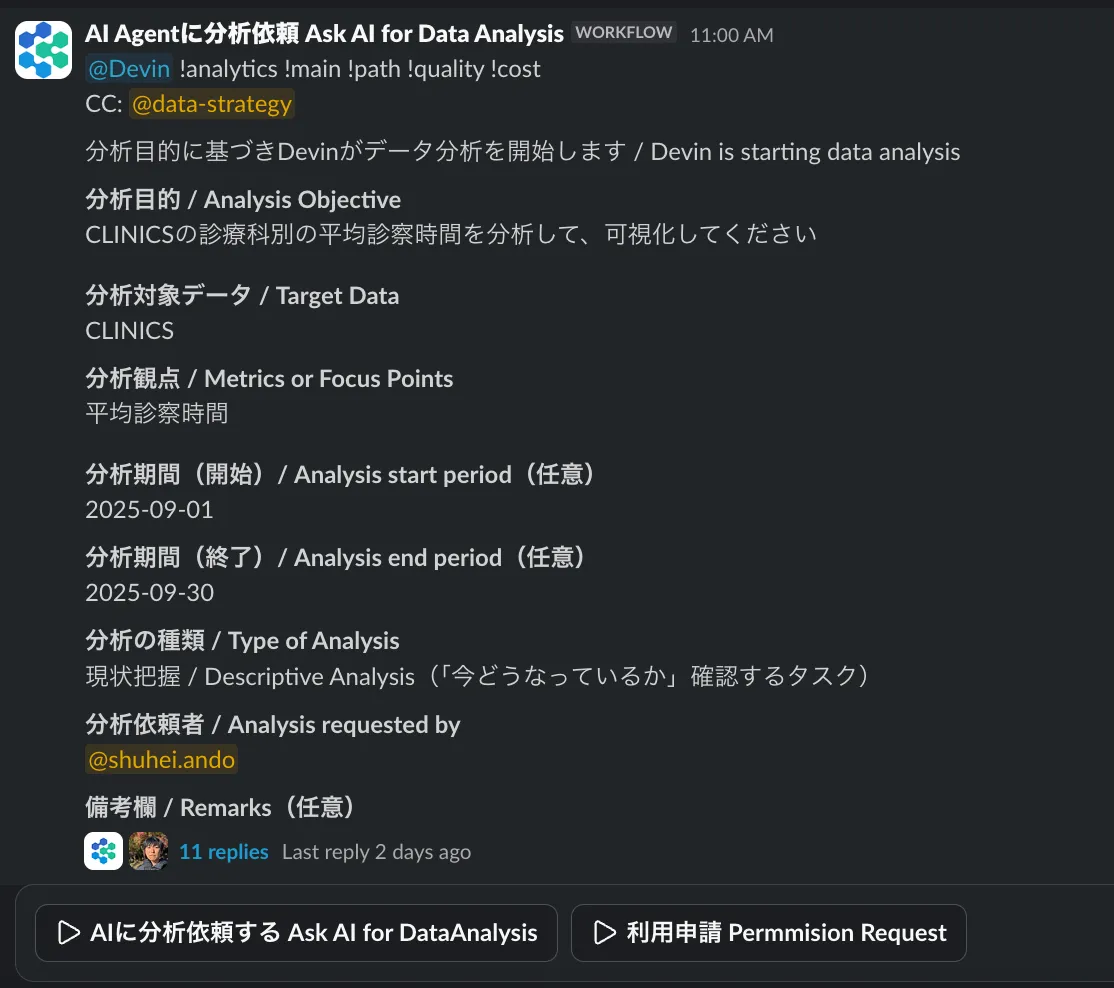
この設計により、ユーザーは「どんな分析をしてほしいか」を構造的に伝えられるようになり、AIエージェントは迷わず適切な分析パスを選択できます。
Devin Macroの活用
フォーム送信時には、Macroを用いてPlaybookパスを自動選択し、依頼内容を構造化した形でDevinに渡します。
これにより、以下のようなワークフローが実現されます。
- ユーザーがSlackフォームで依頼を送信
- MacroがPlaybookの該当セクションを特定
- 構造化された依頼 + Playbookパスの情報がDevinに送信
- DevinがKnowledge Repositoryを参照しながら分析を実行
工夫のポイントは、自由度と制約のバランスです。
フォームによる構造化は「制約」ですが、その制約がユーザーに適切な依頼方法を示す効果も持ちます。
② AIエージェント実行:Devinの活用
Devinは、AIエージェントとして分析タスクを自律的に実行します。
Slackから受け取った構造化された依頼に基づき、以下のプロセスで分析を進めます。
自律的な分析タスクの実行
Devinは、単に質問に答えるだけでなく、以下のような複雑なタスクを自律的に遂行します。
- タスクの理解とプランニング: 依頼内容を解釈し、必要な分析ステップを計画
- ツールの選択と使用: MCPや分析パッケージなど、適切なツールを選択
- データアクセス: MCP Serverを通じてデータウェアハウスに接続
- 分析の実行: SQLクエリの作成、データ加工、グラフ作成
Knowledge Repositoryとの連携
Devinは、分析実行時にGitHubのKnowledge Repositoryを常に参照し、以下の情報に基づいて適切な判断を行います。
- Playbook: 分析の作法、コスト最適化、品質ゲート
- Product Knowledge: プロダクト固有のビジネスロジックとKPI定義
この連携により、Devinは単なる汎用的なAIエージェントではなく、組織固有の分析ノウハウを持つ専門的なデータアナリストとして機能します。
③ Context Engineeringの実践
Prompt Engineeringが「どう尋ねるか」に焦点を当てるのに対し、Context Engineeringは「どんな知識を与えるか」に焦点を当てます。
Knowledge Repositoryの利点は、再現性、保守性、チーム管理のしやすさです。
プロンプトに知識を埋め込むのではなく、外部化された知識リポジトリとして管理することで、チーム全体で知識を共有し、継続的に改善できます。
私たちのContext Engineeringへの取り組みの詳細は、以前の記事「データ戦略グループにおけるcontext engineeringの取り組み」でも紹介しています。
GitHubをSSOTとした知識管理
私たちは、GitHubリポジトリをSingle Source of Truth(SSOT)として、分析AIエージェントが参照する全ての知識を一元管理しています。
knowledge-repository/
├── agent/
│ ├── playbook/
│ │ ├── playbook-main.md # メインフロー
│ │ ├── playbook-paths.md # 分析依頼に応じた分析パス
│ │ ├── playbook-cost.md # BigQueryコストの最適化
│ │ └── playbook-quality.md # 分析における品質と禁止事項
│ └── configurations/
└── product_knowledge/
├── product_a_knowledge.md # Product Aのドメイン知識
├── product_b_knowledge.md # Product Bのドメイン知識
├── product_c_knowledge.md # Product Cのドメイン知識
...etcこの構造化により、AIエージェントは必要な知識を的確に参照でき、チームメンバーは知識の追加と更新を容易に行えます。
Playbookの設計思想
Playbookは、データアナリストの思考プロセスを再現することを目的に設計されています。
責務の分割
単一のPlaybookファイルではなく、目的別に分割することで保守性を高めています。
- playbook-main.md: 分析の基本フロー
- 分析の目的を明確化
- データ品質をチェック
- BigQueryコストを見積もり
- アウトプットから逆算して分析パスを選択
- playbook-paths.md: 3つの分析パスの定義
- Fast: 既存のmartモデルのみを使用、低コスト
- Standard: 中間テーブルを参照、バランス型
- Deep: 複数のレイヤーのデータを参照、高精度・高コスト
- playbook-cost.md: コスト最適化戦略
- クエリ実行前のドライラン
- パーティションとクラスタリングの活用
- 全量スキャンの回避
- playbook-quality.md: 品質ゲートと禁止事項
- 集計前のデータ件数確認
- NULL値の扱いの明示
- 結果の妥当性チェック
この分割により、各Playbookは独立して更新でき、特定の目的(例: コスト削減)に特化した改善が容易になります。
Product Knowledgeの役割
各プロダクトには、固有のビジネスロジックやドメイン知識があります。これらを product_knowledge/ 配下にMarkdownファイルとして整理しています。
例えば、 product_a_knowledge.md には以下のような情報が含まれます。
- プロダクトの概要とビジネスモデル
- 重要なKPI定義
- よくある分析パターン(リテンション分析、コホート分析など)
- データの特性や注意点
AIエージェントは、依頼フォームで指定されたプロダクトに応じて、該当するProduct Knowledgeを参照し、適切な分析を行います。
④ データ基盤:AIに最適化されたデータ設計
分析AIエージェントが効率的に動作するためには、AIが理解しやすいデータ構造が不可欠です。私たちは、dbtを用いてデータウェアハウスのモデリングを行い、階層的なデータ構造を構築しています。
3層のデータ構造
データウェアハウスは、以下の3層で構成されています。
- staging(加工処理データ): 各種データソースを加工処理したデータ
- intermediate(中間層): データクレンジングや結合を行った中間テーブル
- mart(分析用データマート): ビジネスロジックを適用し、分析に最適化されたテーブル
この階層化により、スピードとコストのトレードオフを明示的に管理できます。
実際の動作と効果
Slackで分析を依頼すると、以下のような流れで結果が返ってきます。
- ユーザーがフォームで依頼を送信(所要時間: 1分)
- DevinがKnowledge Repositoryを参照しながら分析を実行(Fast: 5分、Standard: 30分)
- 分析結果がSlackスレッドで返却(グラフや数値サマリ付き)
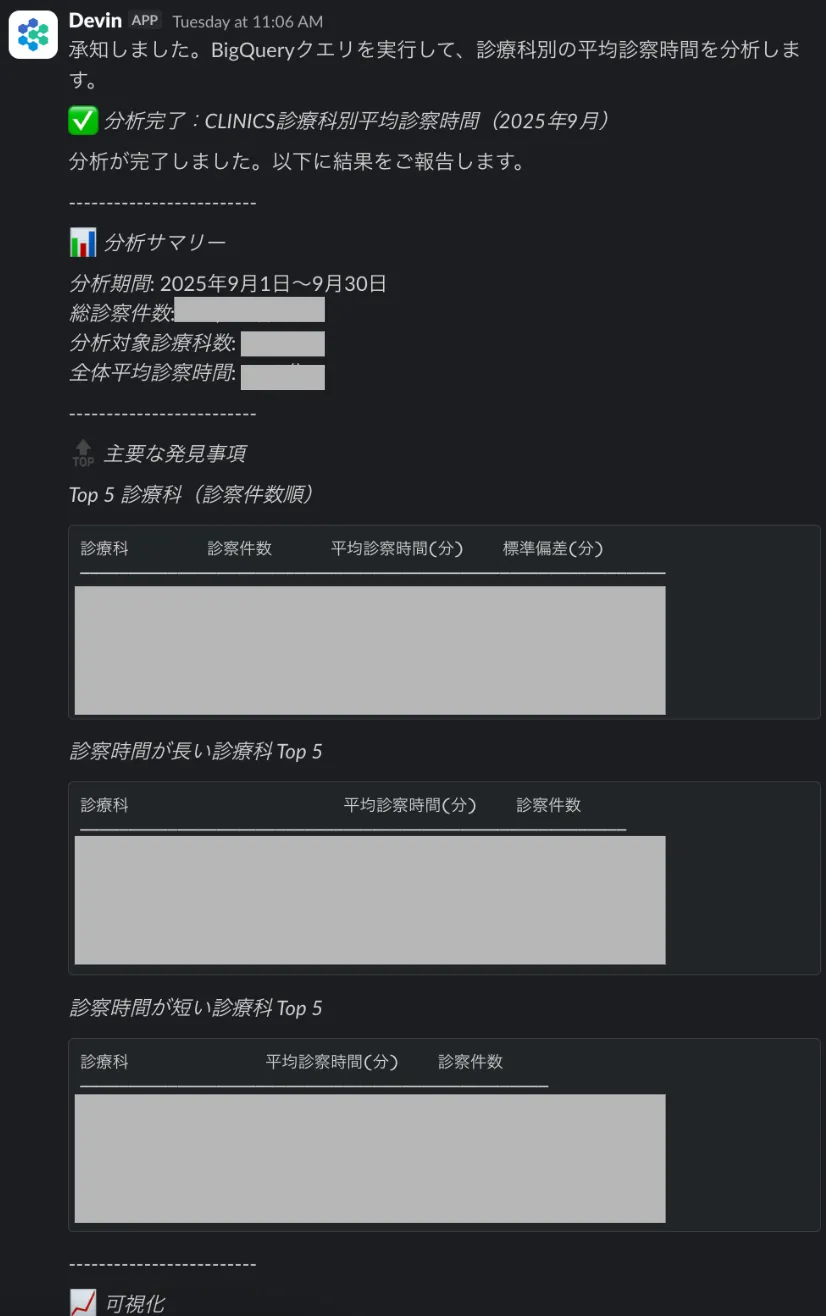
社内リリースからまだ日が浅く、現在も試行錯誤を続けています。
ビジネスユーザーからのフィードバックをもとに、Playbookの改善やProduct Knowledgeの拡充を継続的に行いながら、より多くの分析ニーズに対応できるよう取り組んでいます。
AIエージェントと人間アナリストの役割分担
分析AIエージェントは、全ての分析業務を代替するものではありません。分析の複雑性と工数に応じて、適切な役割分担が重要です。
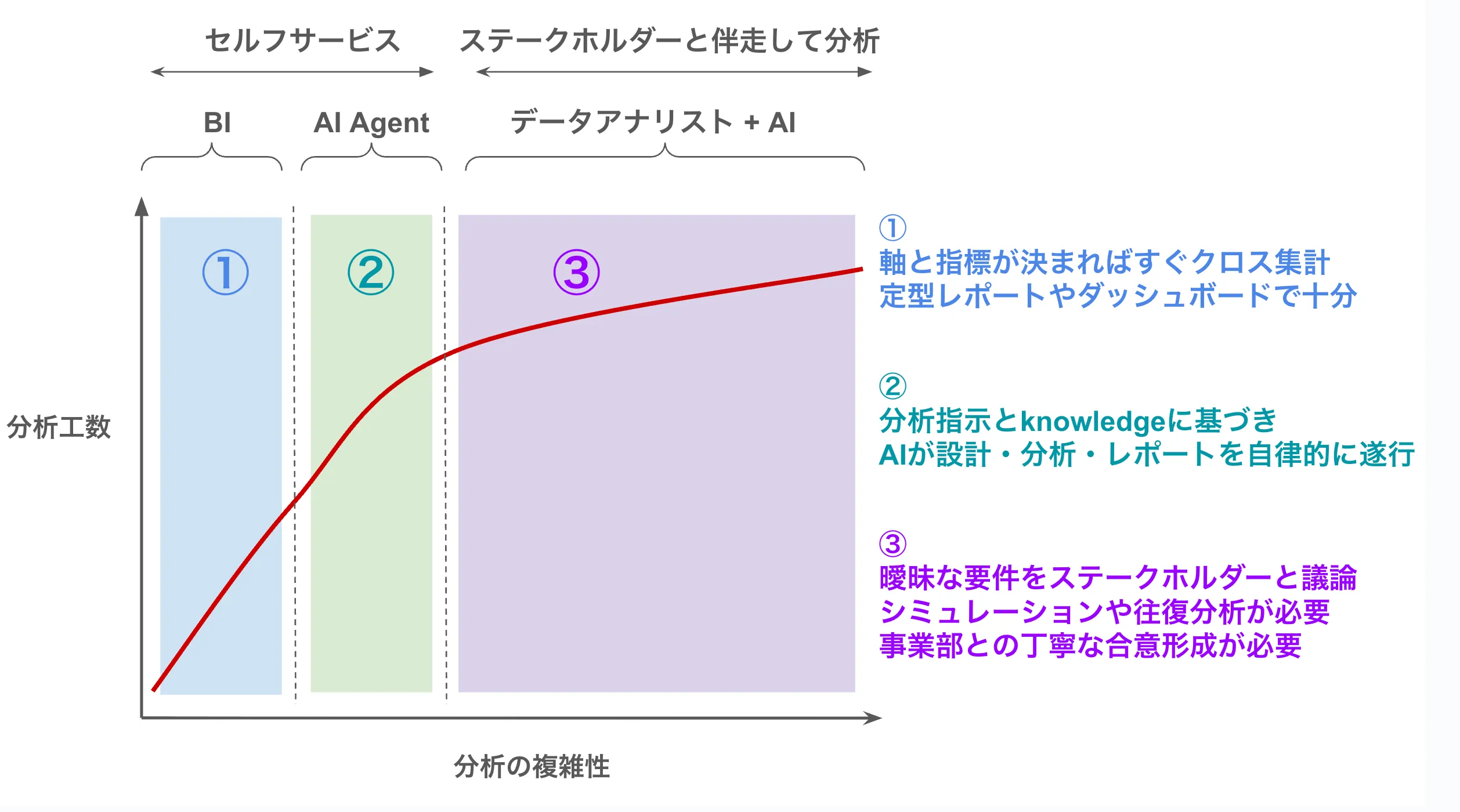
分析業務は、その複雑性に応じて3つの領域に分類できます。
- BIツール: 定型レポートやダッシュボードでの即座な確認
- AIエージェント: 本記事で紹介した領域。アドホックな集計や探索的分析を自律的に実行
- データアナリスト + AI: 曖昧な要件の明確化やシミュレーション、戦略的な意思決定支援
現在、AIエージェントは②の領域を中心に活用されており、定型的で構造化された分析を効率化することで、人間アナリストが戦略的な分析に集中できる環境を作っています。
今後の展望
現在の分析AIエージェントは、一部プロダクトに対応していますが、今後は以下のような拡張を計画しています。
- データソースの拡充: セールスやマーケティングデータへの対応
- 横断的な分析: プロダクトデータとセールスデータの統合分析
- より高度な分析手法: 機械学習モデルの適用や予測分析
本記事では、Slack、Devin、Context Engineeringを組み合わせた分析AIエージェントのアーキテクチャと設計思想を紹介しました。
データ分析AIエージェントの開発に取り組む方々の参考になれば幸いです。
We’re hiring!
メドレーの医療プラットフォーム本部のデータ戦略グループでは、AI 時代の新しいデータ分析にチャレンジしたいデータエンジニアを募集しています。医療ヘルスケア領域でのAI×データ活用にご興味をお持ちの方は、ぜひお気軽にお声がけください!