はじめに
はじめまして、人材プラットフォーム本部 データマネジメントグループ の山邉 (@beniyama) です。2025年4月からデータエンジニアとしてメドレーに参画し、データ基盤の開発からデータ分析まで幅広く活動しています。
データ基盤上で広告配信に関わるデータを扱いたい場面は多いと思いますが、今回 Google 広告のデータを BigQuery Data Transfer Service(以下 DTS) で BigQuery に連携したらデータモデリング観点で学びがあったのでご紹介します。
この記事でお伝えしたいこと
- BigQuery Data Transfer Service で Google 広告のデータを簡単に連携できるということ
- 膨大なテーブルが生成されるが、データモデリングの構造や命名規則などのポイントを理解すれば容易に扱えるということ
- テーブルとビュー
- ディメンジョンとファクト
- セグメントとメトリクス
- データ基盤の利用者にとってわかりやすいデータモデリングとは?について考える良い題材だったということ
マーケティング関係の方はもちろん、データエンジニアやアナリティクスエンジニアの方々にも何かのご参考になれば幸いです。
※ 本稿で言及しているサービスのバージョンやサポート状況、また料金設定などは執筆時点(2025-07-08)のものであることにご注意ください。
Google 広告のデータを DTS で BigQuery に連携する
DTS : BigQuery Data Transfer Service とは
DTS はその名の通り、GCP (Google Cloud Platform) で提供されているマネージドなデータ転送サービスです。GCP コンソールから数クリックで、BigQuery と様々なシステム間のデータ連携を実現することができます。またスケジューリング設定や過去遡及機能など、データ連携処理に必要な一連の機能が備わっている他、Google 社の提供するサービスを中心に多くのコネクタが用意されているのも嬉しいポイントです。
特に Google 広告に関しては Google 広告の転送 に記載がある通り、P-MAX キャンペーン を含む詳細なレポート情報を取得できることが特徴です。内部的には Google Ads API を利用しており、必ずしも API の最新バージョンをサポートしているわけではない点に注意が必要ですが、不変的なメトリクスを見るのが主目的であれば問題になることは少ないかと思います。
なお、DTS は連携するデータソースによって料金設定があることに注意が必要ですが、現時点では Google 広告転送自体は無料となっています(BigQuery のストレージコストなどは別途発生しますので、詳細は Google Cloud 社にお問い合わせください)。
Google 広告データの連携設定
基本的には Google 広告の転送 に記載の通りですが、データ転送の設定にあたって GCP と Google 広告 双方での権限付与が必要です。
- 今回の設定を行うユーザー : DTS によるデータ転送設定の作成権限(
bigquery.transfers.update) - 転送設定に使われるユーザー(サービスアカウントなど)
- 読み取り対象となる Google 広告アカウントへの読み取りアクセス権限
- 書き込み対象となる BigQuery のデータセット書き込み権限(
bigquery.datasets.get/bigquery.datasets.update)
特に、DTS 実行をサービスアカウントで行う場合には Google 広告側でサービスアカウントに権限付与を行う必要があるため、ご注意ください。
DTS の設定画面は BigQuery に統合されており、BigQuery > Pipelines & Integration > Data transfers にあります。
ここでは Google 広告の Customer ID を設定する他、取得対象とするテーブルの絞り込みや、毎回の連携で過去何日分を洗い替えるかといった項目が設定可能です。Report type を Custom にすると GAQL(Google Ads Query Language) という Google 広告データの取得に特化したクエリ言語で、必要なデータ抽出・加工して取得することが可能なようです。
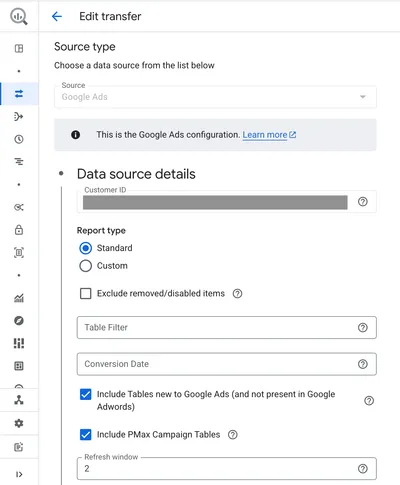
ちなみにここで Conversion Date という項目がありますが、これは CVR などで使われるコンバージョンではなく、旧 Google アドワーズから Google 広告に切り替えた(= コンバートした)日を指しているようです(新規の転送設定では不要)。
またこの後には BigQuery の転送先データセットやスケジュール実行の設定、サービスアカウント設定などが続きます。
設定はこれだけですので、とても簡単に使えそうな雰囲気が伝わるかと思います。
Google 広告のデータモデル
BigQuery に作成されるデータセット
さて、問題はここからです。Google 広告のデータをフィルタリングせずに連携すると、そのテーブルの多さにまず圧倒されるはずです。
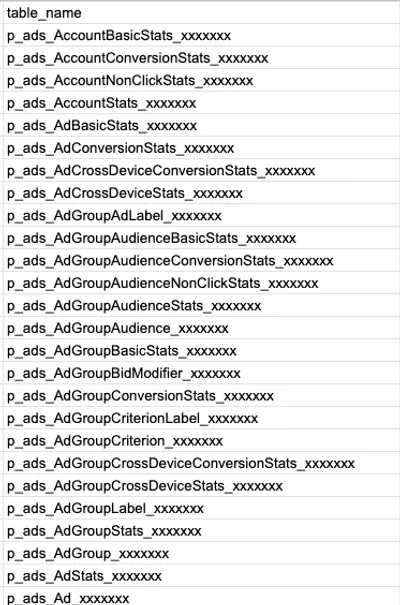
これは INFORMATION_SCHEMA から今回作成したデータセット情報を出したものですが、数えてみたら 81 個のテーブルと 28 個もの ビューが作成されていました。
これだけあると一体何をどう扱えば良いのか…と途方に暮れそうですが、実は非常にわかりやすいルールに従って設計されているので、それが理解できると容易に扱えるようになります。
データモデルの読み解き方
まずは、『Google 広告との連携』の『データモデル』 に ERD があるのでそちらを確認しましょう。レポートの変換 には Google 広告および API と BigQuery 上のテーブルのマッピングが記載されているので、こちらも参照されることをお勧めします。
また、これからご紹介するポイントをまとめた図が下記になります。
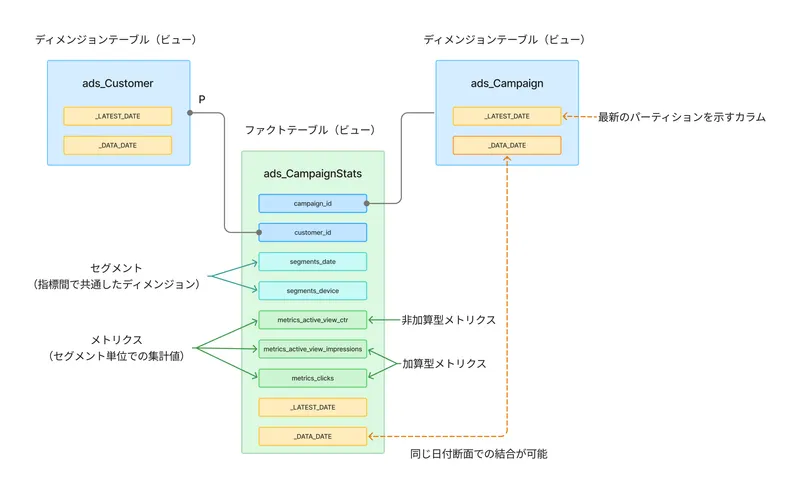
それでは個々のポイントについて見ていきましょう。
テーブルとビュー
まず先ほどのテーブルとビューですが、ビューの定義を開いてみるといずれも
SELECT
*,
DATE ('2025-07-06') AS _LATEST_DATE,
DATE (_PARTITIONTIME) AS _DATA_DATE
FROM
`<Project ID>.<Dataset ID>.p_ads_AdBasicStats_<Google Ads Account ID>`のようになっており、この例では p_ads_AdBasicStats という元テーブルに対して、各レコードの集計対象日(_DATA_DATE)と最新の集計対象日(_LATEST_DATE)を付与しているだけということがわかります。
なのでビューのことは一旦忘れて大丈夫なのですが、ポイントが3点あります。
_DATA_DATEと_LATEST_DATEのような共通した名称のカラムを付与することで、エンドユーザーは異なるテーブルであっても同じようにデータを扱うことができる- 各レコードは集計対象日ごとに日付パーティションに格納されており、かつビューに共通で付与された
_DATA_DATEを合わせることで、断面(集計日)を揃えた JOIN が可能 - エンドユーザーへのインタフェースは
ads_xxxというビュー、実体のあるテーブルはp_ads_xxxという命名で一目でわかるようになっている
パーティションに関しては DTS の設定において利用者が意識することはなく、冪等性も担保されているため連携するたびにレコードが増えて…みたいなことももちろんありません。
ディメンジョンとファクト
また、Google 広告のデータはスタースキーマと呼ばれるデータモデルを採用しています。スタースキーマにはファクトテーブルというクリック数のような数値指標を記録するテーブルと、ディメンジョンテーブルという国やデバイスといった分析軸を記録するテーブルがあります。
Google 広告のデータに関しても同様で、下記のようなカテゴリ分けが可能です。
- ファクトテーブル :
ads_ClickStats(クリック数)やads_HourlyAdGroupConversionStats(毎時単位のコンバージョン数)の集計値が記録される - ディメンジョンテーブル :
ads_Ad(広告マスタ) やads_Customer(顧客マスタ) のようにファクトテーブル内に含まれる ID と JOIN することで軸別の集計が可能になる
ここでは
Statsという接尾語の有無でファクトテーブルかどうかを判別が可能- ファクトテーブルは最小粒度での集計値で構成されている
- ファクトテーブル内に埋め込まれたディメンジョン情報もある
の3点がポイントになります。スタースキーマのモデルには fct_xxx や dim_xxx といった命名規則がよく使われるので 1 はわかりやすいと思いますので、2 と 3 について次節で詳しく見ていきます。
注意点
ディメンジョンテーブルには日別で各時点でのスナップショットが蓄積されていますので、例えばキャンペーン名などを取得するときは LAST_VALUE を使うなどする必要があります。
セグメントとメトリクス
ファクトテーブルの例として、ads_CampaignStats の中は下記のようなカラム(一部抜粋)で構成されています。
| フィールド名 | 型 |
|---|---|
| campaign_id | INTEGER |
| customer_id | INTEGER |
| metrics_active_view_cpm | FLOAT |
| metrics_active_view_ctr | FLOAT |
| metrics_active_view_impressions | INTEGER |
| … | |
| segments_date | DATE |
| segments_day_of_week | STRING |
| segments_device | STRING |
| segments_month | DATE |
| segments_quarter | DATE |
| segments_week | DATE |
| segments_year | INTEGER |
| _LATEST_DATE | DATE |
| _DATA_DATE | DATE |
ファクトテーブルのカラムには大きく分けて以下の4種類があることがわかります。
- ディメンジョンテーブルへの結合キー(campaign_id、customer_id など)
metrics_xxxという集計値(メトリクス)segments_xxxという埋め込みディメンジョン(セグメント)_LATEST_DATEや_DATA_DATEといったパーティションキー
そしてここでのポイントは
- 日時ディメンジョンやデバイス種別のような、各指標に共通なディメンジョンは予めセグメントという形で埋め込まれている
- セグメントがメトリクスを分解する最小単位であり、またディメンジョン単位での集計でも正しく非加算型メトリクスを算出できるように加算型メトリクスが用意されている1
になります。
1 については、ファクトテーブル化をする際に全てディメンジョンとして切り出すのではなく、共通セグメントを定義することで不要な JOIN を減らせますし、また集計の最小単位をエンドユーザーに明示することができます。
また 2 に関しては、例えば metrics_active_view_ctr(Active View CTR : 視認可能なインプレッションに対するクリック率)は segments_device_A と segments_device_B の値を単純に足し合わせたりはできない非加算型メトリクスですが、一方で metrics_clicks と metrics_active_view_impressions という(CTR を算出するために必要な)加算型メトリクスも提供しています。
これにより、例えば下図のようにドリルアップ(データの集計レベルを上げること)して全てのデバイスを集約したメトリクスを取得したいときも、segments_device_A と segments_device_B の metrics_clicks の和、および metrics_active_view_impressions の和をそれぞれ算出できるので、metrics_active_view_ctr を適切に再計算することが可能です。
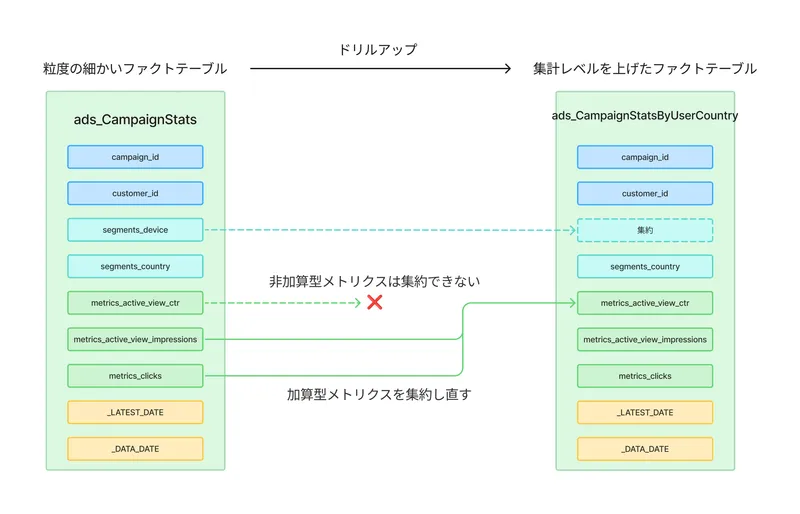
例えば下記のような SQL で、 Google 広告コンソール上の値と同じ(セグメント別に分けていない)キャンペーンの統計情報を取得することができます。
SELECT
segments_date,
SUM(metrics_impressions) AS metrics_impressions,
SUM(metrics_conversions) AS metrics_conversions,
SUM(metrics_cost_micros / (1000 * 1000) * 1.12) AS metrics_cost,
SUM(metrics_clicks) AS metrics_clicks,
(SUM(metrics_cost_micros) / (1000 * 1000)) / SUM(metrics_clicks) AS cpc -- 非加算型メトリクス
FROM
`<GCP Project ID>.<Dataset ID>.ads_CampaignStats_xxxxx`
WHERE
campaign_id = <キャンペーン ID>
GROUP BY
segments_date
ORDER BY
1 ascセグメントという形で集計の最小単位を揃え、かつ加算型メトリクスを入れ込んでおくことで、集計レベルを上げたときも非加算型メトリクスを再集計できるようになるという考え方は、データ基盤を開発される方にとって参考になる点も多いのではないでしょうか。
注意点
一部セグメントは排他的なメトリクスになっておらず、例えば clickTypes(ユーザーが広告のメインエリアとサイトリンク表示オプションのどちらをクリックしたか)でセグメントが切られている場合、両方に同じ impression 数が入る仕様になっています。
そのため AdGroupStats などでは WHERE clickType = "URL_CLICKS" などの条件を付加して一部の値に絞る必要がありますので、実際の数値をよく確認されることをお勧めします。
まとめ
今回は Google 広告のデータを BigQuery Data Transfer Service で転送する際の、連携方法やデータモデルについてご紹介しました。BigQuery で取り扱うことで、より細かい広告効果の評価が可能になります。
また、Google 広告のデータモデルは一見複雑に見えますが、ファクトテーブルとディメンジョンテーブル、セグメントとメトリクス、そしてそれらを表す命名規則といったポイントに着目すると非常に理解しやすいです。また実践的なプラクティスが詰まっていると思いましたので、データモデリングの参考にしたり、チームでの議論のお題として活用されるのはいかがでしょうか。
We’re hiring!
現在、人材プラットフォーム領域ではデータ組織を立ち上げ、データ基盤の構築から事業における利活用推進まで幅広く活動をしています。
『医療ヘルスケアの未来をつくる』というミッションのもと、医療介護領域における人材採用・研修の支援を一緒にしていただけるデータエンジニア・データアナリストの方々を募集しておりますので、ご興味お持ちいただけたらカジュアル面談からでもぜひお声がけください!
脚注
-
本稿では、iPhone や Android のように排他的に分割されたセグメントについて、クリック数のように足し合わせても問題のないメトリクスを加算型、一方クリック率のように単純に足し合わせられないものを非加算型として記載しています。 ↩