はじめに
こんにちは。 人材プラットフォーム本部プロダクト開発室第一開発グループの阪本です。
毎日夕方になっても 30 度を超えるような猛暑が続く中、皆さんはいかがお過ごしでしょうか?
今まで何度も紹介させていただきましたが、私は阪神タイガースのファンです。 今年は第二次岡田政権の 1 年目、開幕からの好調を維持し交流戦までは首位独走。交流戦明けに一時的に首位を明け渡す事態になりましたが、8 月に入り破竹の 2 桁連勝で首位奪還どころか独走状態という最高のシーズンを迎えております。
投手は元々良いチームではありましたが、今年は課題であった守備と出塁率に改善が見られ 普通にやれば勝てる チームに近づいたというのが大きいのではないでしょうか。
この記事が公開される頃には優勝マジックが点灯し、18 年振りの「あれ」まで秒読みとなっていることでしょう。待ちに待ったその瞬間まで、あと少しです。

さて、現在私は SRE Unit リーダの立場で主にジョブメドレーの安定稼働に向けた取り組みに日々取り組んでいます。 今回はチーム内で抱える課題と、それを解決するための取り組みについて紹介させていただきます。
SRE Unit が取り組んでいる課題
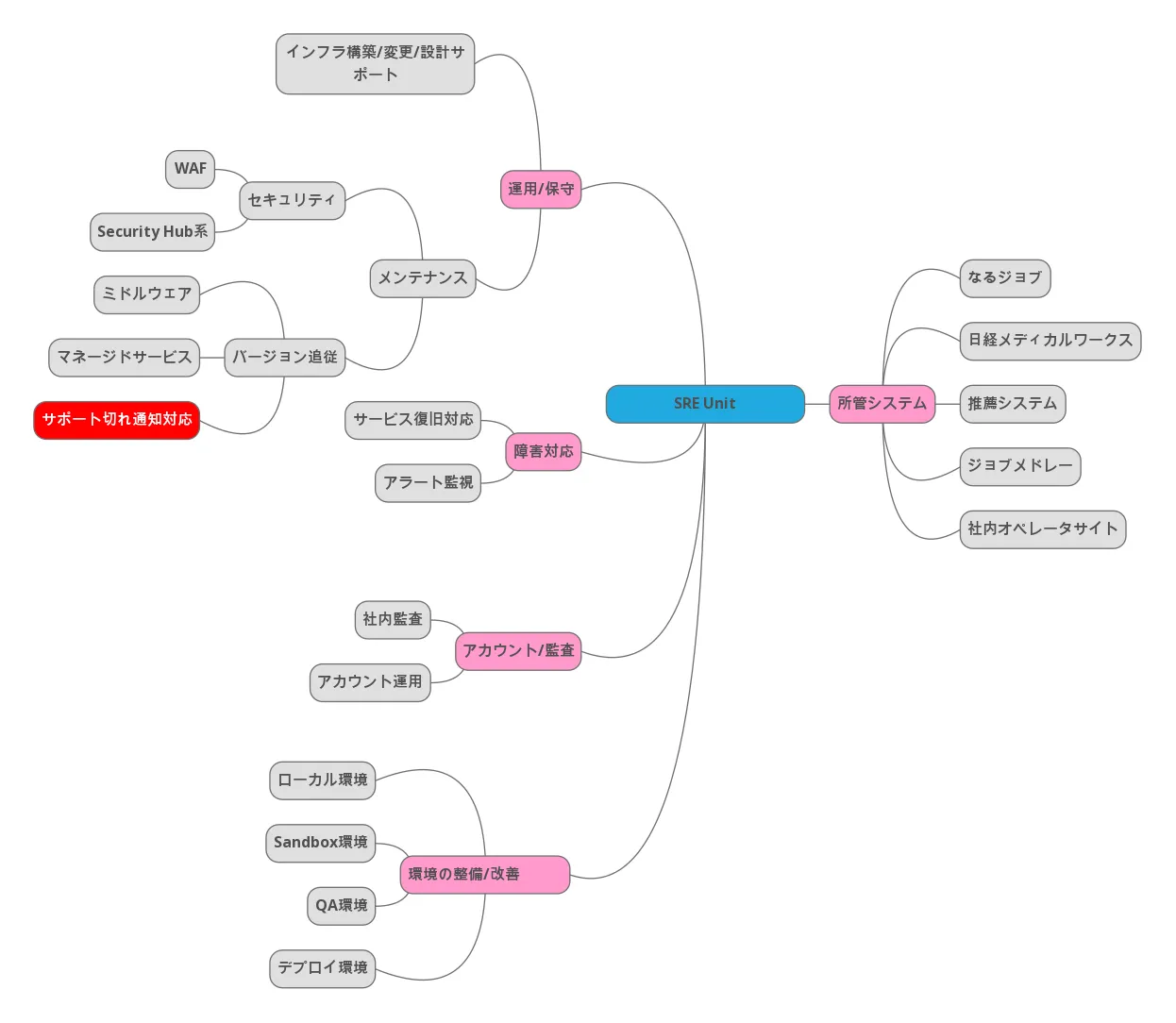
SRE Unit の業務は
- 運用/メンテナンス
- 障害対応
- アカウント管理
- 環境整備
と多岐に渡り、ジョブメドレーを含めた大小 5 システムを対象として 4 名のメンバーで推進しています。
この中でも最近の SRE Unit での業務の大半を占めるものがリソースのバージョン追従対応ですが、明確な期限が存在する上に対象システム/リソースは多いといった特徴があるため、計画的に行動しないと突発業務が発生した際に期限内の対応が困難になります。
特に AWS といったマネージドサービス系はアップデートが強制的にスケジューリングされるため、こちら側の都合を挟む余地はありません。 こういった事態にならないために行なっている SRE Unit での この先に何が起こるのか? という「予測/計画」と、計画を阻害する要因 となる「突発作業の削減」の 2 軸の取り組みについて紹介します。
バージョン追従対応とは?
まずは前情報としてバージョン追従作業というものがどういったものなのかを説明します。
これはシステムが利用しているサーバ/データベースといったリソースのサポート期限終了 (EOL:End Of Life) までに最新バージョンに引き上げることを指します。

EOL を迎えたリソースは公式でのサポート終了を意味するものであるため、以降発生するバグや脆弱性に対しての修正対応が期待できない状態になります。
バージョンアップ対応を行わない場合、運良くバグや脆弱性の問題が発生しなければソフトウェア的に動作の継続は可能ですが、これに関連するライブラリなども古いバージョンのサポートを切るタイミングが出てくるので遅かれ早かれ影響は出てきます。
また AWS のマネージドサービス (ex.RDS/ElastiCache/OpenSearch) では、サポート期限の終了に伴い強制的に最新バージョンへの更新がスケジュールされます。
「最新バージョンへと更新してくれる」、その言葉だけ見ると素晴らしいものですが、もちろん更新中に発生するダウンタイムや接続するアプリケーションに対する影響まで面倒は見てくれません。
そのため、マネージドだろうが非マネージドだろうがバージョンアップ対応は必ず行う必要があると言うことです。
作業の内容
この作業は単純にリソースのバージョンアップをするだけで済む作業ではありません。
前述でのダウンタイムやバージョン間による変更差分によりアプリケーションが今まで通り動いているかを保証する必要があるため、下記をセットで実施することでシステム稼働を担保しています。
- 新旧バージョンの変更履歴を把握
- 変更によるアプリケーション影響の把握
- アプリケーションの動作チェック
- 負荷チェック
- 移行計画の策定
- 移行作業の実施
取り組み 1.予測/計画
これらの作業は決して少ない工数では無く、システムやリソースの増加に伴って作業量も増えていく一方です。
AWS であれば EOL 通知はメール等で行われるため今までは通知が来てから計画を立てるというフローを採っていましたが、対象システムの増加に伴うリソース増により上記内容を期限内に消化するのが困難になってきています。
さらに RDS for MySQL に関してはバージョンあたりのサポート期限が短縮傾向にあるため、一度バージョンを上げればこの先数年は安泰といった状態でも無くなってきています。
この状態を踏まえて、2023 年からは通知が来る前に先手を打つ方針に切り替えました。 いつ何が起きるのか?(どれがいつ EOL を迎えるのか?)を事前に把握し、それを元に逆算し計画をすることで無駄の無い行動を目指すというものです。
対象リソースのリストアップ
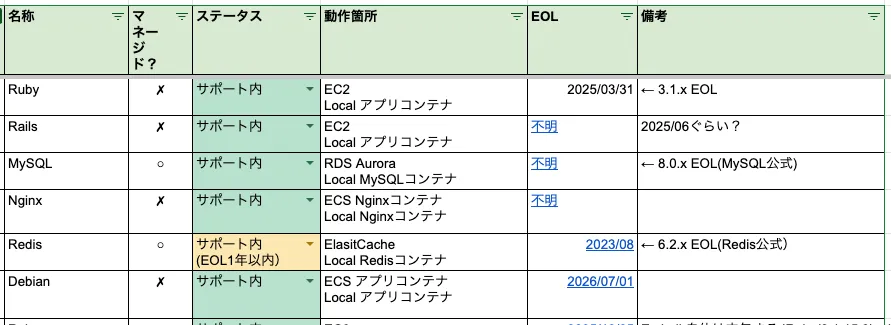 まずは各システムが利用するリソースのバージョンと EOL をリストアップし、自分たちが抱えるシステムとリソースの全量とそれらのバージョンがどういった状態なのかを把握します。
まずは各システムが利用するリソースのバージョンと EOL をリストアップし、自分たちが抱えるシステムとリソースの全量とそれらのバージョンがどういった状態なのかを把握します。
ここから各バージョンの EOL 時期を収集することになるのですが、幸いバージョン EOL については個々の公式サイトで明記されていることが多いので把握はそれほど難しくはありませんでした。
ex.)
AWS といったマネージドサービスに対しては公式の EOL と必ずしもイコールにはなりませんが、マネージドサービス側が公式 EOL より期限が早いことは無いので、公式 EOL を期限として考えるようにしています。
また公式サイトが見つからない/明記されていないといったものが稀にあり、それらは endoflife.date というサイトを活用しました。
優先度の決定
リストアップした時点でかなりの量に及ぶため、ここから対応優先度を決定します。
最優先とすべきポイントとしては、期限を迎えると強制的にバージョンアップされてしまうマネージドサービス系のリソースです。
これらについては切られた期限に対する猶予は基本与えられないため、優先度が一番高いものと考えます。 次点として EC2 に自前でインストールするようなリソースが続きます。これは最悪 EOL を迎えても動作は継続できるため、上記よりは優先度を下げています。
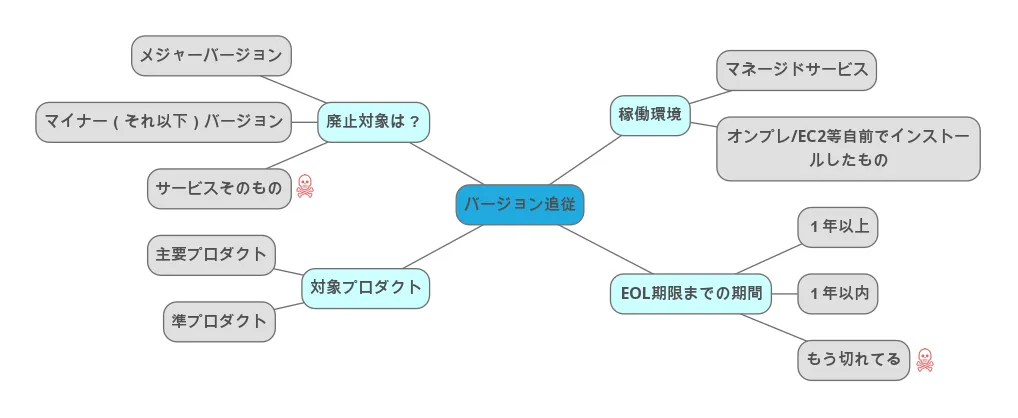
後はこれらの 優先度/EOL の 2 軸で対応順を検討し、2023 年の年間スケジュールに落とし込みました。
効果
2023 年 8 月の時点で、AWS のマネージドサービス系のリソースについては通知を受ける前にバージョン追従作業を済ませることができています。
特に 2023 年 10 月に EOL を迎える RDS の MySQL5.7 → MySQL8.0 対応は大変大きな規模の作業になりましたが、対象 4 サービス、DB インスタンス十数台を 2023 年 7 月に無事すべて切り替えることができました。
途中 AWS では OpenSearch や ElastiCache の緊急セキュリティアップデート対応が突発で入りましたが、全ての計画において先手というバッファを見込んでいたため予定を大きく狂わせず完了することができています。
取り組み 2.突発作業の削減
先程は計画を立てて無駄のない行動を目指すことを目的としていましたが、どれだけ予測や計画の精度を上げた所で突発作業はどうしても発生します。
社内からの要因であれば対処の仕方もありますが、外部要因となると予測も対応も困難であるものが多くなります。 特に「何も変更していないのに急に動かなくなった!」が一番脅威で、OS 仕様変更や外部ライブラリの廃止に伴うものがチームの実績として多く感じています。 こういった外部要因による事象を発生させにくい状態にするため、以下の対策を行っています。
PrivateGem サーバの構築
ジョブメドレーは Ruby で動くアプリケーションですが、外部ライブラリとして多数の Gem を併用しています。
この Gem がある日突然リポジトリから削除され bundle install が通らず起動しない、といったことが稀にありました。
バージョンアップで対応できるものであればまだ良いのですが、そもそも廃止といった状況だと対応の長期化は必至。
そういった事態を避けるため Geminabox にて PrivateGem サーバを構築しました。
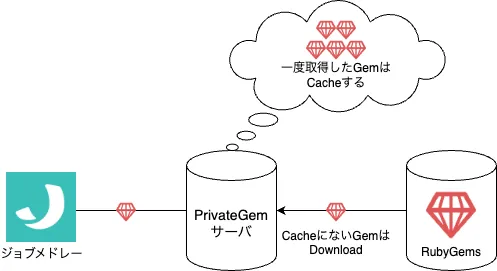
このサーバは RubyGems 向けの Proxy/キャッシュサーバ という位置づけで、このサーバ経由で RubyGems に Gem を取得すると同時にサーバ内にも Gem はキャッシュします。
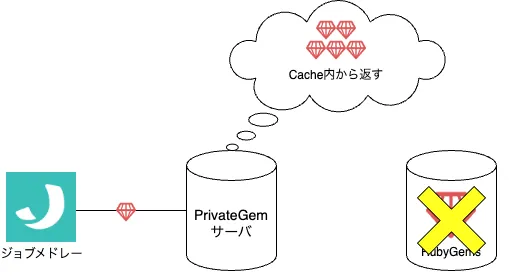
キャッシュされた Gem については以降 RubyGems に再度取りに行くことは無いため、RubyGems 上で取得できない事態が発生しても喫緊の対応が必要な状況にはなりません。
動作環境の Docker イメージ化
とある Python によるプログラムを対象としているのですが OS/Python バージョン/Pip ライブラリ の兼ね合いがとても厳しく、少しでもバージョンにズレが生じると動作不良を起こし対応に回るといったことが年〜半年に一度発生していました。
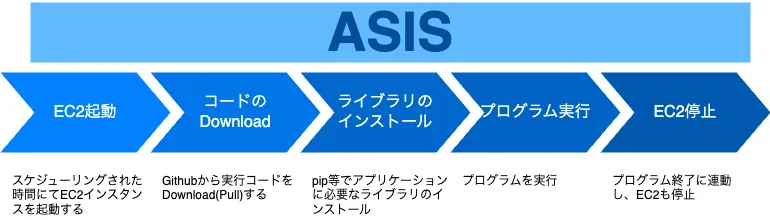
動作環境としては
- プログラム開始時に EC2 起動
- コードのダウンロード
- ライブラリのインストール
- プログラム実行
- プログラム終了後に EC2 停止
という形態を取っていましたが、それぞれのステップに於いて毎度同じ環境になる保証がない状態というのが大きな課題でした。
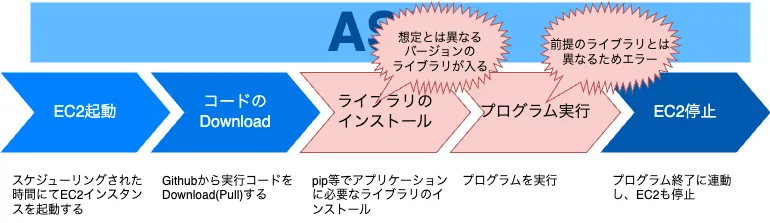
具体的には EC2 の起動時は Amazon Linux 2 の仕様で Python のバージョンが変わって動かない、ライブラリのインストールではバージョン固定が甘くある日バージョンが変わって動かなくなる、といったことが起こる再現性の低い仕組みで組まれている状態です。
そこで、毎回同じ動作環境を維持するための取り組みとして Docker イメージによる環境の固定化を行いました。

これは Docker イメージによって OS を固定した上でイメージ内にコード/ライブラリまでを含めてしまうもので、OS 起動からプログラムの起動まですべて同じ状態になるようにしました。
また副産物としてプログラム起動までのステップが短縮され、プログラム起動までのオーバヘッドの短縮にも繋げることができました。
効果
双方の仕組みの導入により、今年は対象システム回りでの突発作業は発生しない状態を維持できています。
最後に
今回は SRE Unit の業務の一つであるバージョン追従対応についてフォーカスを当てて紹介しましたが、抱える業務は他にも多数あります。
我々 SRE Unit の目的はサイトの安定稼働/信頼性を維持することであり、今回のようなバージョンアップはその中の一部でしかありません。この他にも負荷の監視やパフォーマンスチューニング、障害対応などを取り組むべきことは山ほどあります。 まだチームの人数は決して多くは無いこの現状で、いかにアイデア/技術/仕組み化によって効率的に動けるか切磋琢磨し、より安定したサービスを提供できるように日々取り組んでいます。
もしこれらの取り組みに興味のある方は、是非我々と一緒に働きませんか?
